4. Data Management and Shared Utilities¶
4.1. Introduction¶
The development of the data management framework for executing the DTOcean modules required the development of several supporting python packages. Principally a data management framework was created to handle the requirements for the Core component which was named “Aneris” and, secondly, a utility package that contained a number of functionalities used through all of the Python packages was created called “Polite”. The development and use of these two modules is discussed in this chapter.
4.2. Aneris Framework¶
4.2.1. Objectives¶
The objective of the Aneris framework is to provide the following functionality:
- A single unified collection of scientific data without semantic conflict
- A method for collecting and delivering this data to and from external actors
- A method to store and recall the evolution of data as different actors are interrogated
- Identification of data requirements of external actors and how other actors can satisfy them
- Allowing the connected actors to be run in order and update the data requirements to reflect this
- Comparing matching data across various stages of execution and between simulations
- Provide utilities to support this functionality and analyse the state of the system
Fig. 4.2 shows a UML robustness diagram for the Aneris framework. A robustness diagram divides classes into three stereotypes. The green symbols are boundary types and show how data is added to and retrieved from the system. The blue symbols are entity types and these show the collection and types of information that are used. The red symbols are control types and these can manufacture and access the entities and interfaces in order to carry out tasks required by the user.
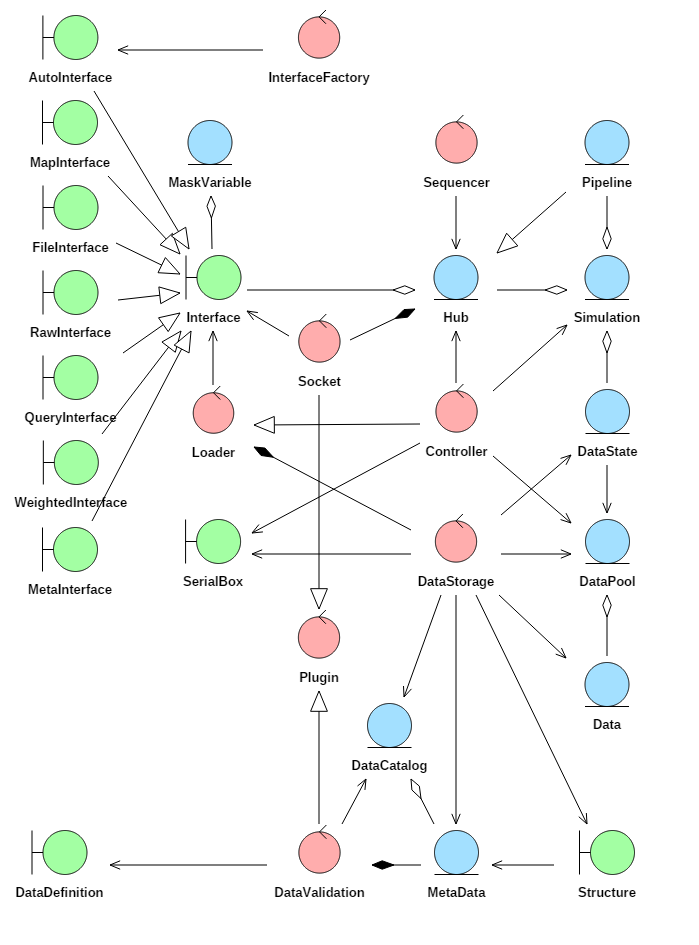
Fig. 4.2 Robustness diagram for the Aneris framework
4.2.2. Definitions, interfaces and the creation of data members¶
When applying the Aneris framework the lowest level of functionality is provided by the Interface and DataDefinition classes. The DataDefinition class is used to read the user provided data definition specification and convert it into a programmatic form. This interface reads a YAML formatted file that can be created directly by the user or using a utility which is available to convert a Microsoft Excel file into the required YAML format. The fields specified in the YAML file must match those defined in the MetaData class which is associated to the DataValidation class. The DataValidation class will check that all fields given in the data definitions match the definitions given in this MetaData class before creating MetaData objects and storing them in the DataCatalog class. An example of data definitions in YAML format is given in Listing 4.1.
---
- identifier: 'demo:demo:high'
label: 'High'
structure: 'UnitData'
- identifier: 'demo:demo:low'
label: 'Low'
structure: 'UnitData'
- identifier: 'demo:demo:rows'
label: 'Rows'
structure: 'UnitData'
- identifier: 'demo:demo:table'
label: 'Table'
structure: 'TableData'
- identifier: 'trigger.bool'
label: 'Trigger'
structure: 'UnitData'
The DataCatalog stores all the valid MetaData objects that have been produced from reading the data definition specification files. This is used to identify, validate and structure all the raw data that is entered through Interface classes. The Interface classes are used to connect to various sources of input which can either be used to create data members, or use data members to undertake a functional task (and possibly alter or create new data members in the process). There are several types of interface available depending of what source the user wishes to connect to: MapInterfaces for general connection with Python packages, QueryInterface for connection with databases, FileInterface for connection with files and RawInterface for basic collection of data from raw input, among others. Each interface has some abstract methods that must be made concrete by the user in order for them to be valid. Note that Interface classes can also be used to write data back to certain actors such as formatted files.
Each Interface subclass is associated to a Socket class and further sub-classing can be used to subdivide the interfaces as required. Socket classes search interfaces to see which data members a class can provide and which it requires in order to execute. Sockets will collect Interface classes for Hub and Pipeline classes so that they can be executed in a defined sequence.
Raw data can be extracted from an Interface class. Alongside the data, the interface will provide the unique ID for the data matched to the DataCatalog. This raw data can then be converted into a data member using the DataStorage class. The DataStorage class will take the raw data and its ID, retrieve the associated MetaData object from the DataCatalog and build a new Data object corresponding to the structure field given in the MetaData object.
The structure field specifies which subclass of the Structure class should be used and it can be sub-classed into as many structures as is required for the project being undertaken. It is important that the given raw data matches the structures specified in the associated Structure class and some validation should be provided within the Structure classes “get_data” method.
4.2.3. Higher level data grouping and execution ordering¶
The above process can be used to create a single data member stored within a Data object and demonstrates the methods used to ensure there are no semantic conflicts whilst communicating between various external actors. Still, the true power of the framework is harnessed when considering storing groups of data together and defining sequences of execution for particular interfaces.
For this task it is necessary to use the Controller class to create a Simulation object. This Simulation object is the container for numerous DataState and Hub or Pipeline objects that are required to facilitate a particular sequence of events. DataStates store groups of data members which are considered to exist at a particular state (or level) of the system. They do not contain the Data objects directly, instead having a reference to the DataPool object which is responsible for memory management. Thus the same, or alternative, members can be stored in another DataState object to show a later state of the system. This structure allows the system to revert to an earlier state or compare between states.
The DataPool class contains all the Data objects created when producing a DataState object. This object serves two purposes; firstly it acts as a structured collection of all of the data that could be serialised (saved to disk) in a single unit. Secondly, because Datastates only contain text based references to Data objects in the DataPool, unnecessary copying of Data can be avoided by sharing references. This will be particularly important when Simulation objects are cloned and share a large percentage of equal valued data.
A Hub or Pipeline can group, record and sequence the execution of Interface objects that are available to a particular Socket. This is particularly useful should one interface be dependent on the outputs of another and enforces a logical order. The Sequencer class can be used to create the sequencing within the Hub or Pipeline and the Controller class can create reports detailing whether the inputs for particular interfaces must be satisfied by the sequence itself or must be provided by other external actors (like the user or database) or whether outputs have been overwritten by later interfaces in the sequence.
The outcome of these two capabilities is that a record of the evolution of the data can be stored within a Simulation object and that record can be recalled, modified and re-executed as is required by the system user or optimisation sequence, utilising the Controller, Simulation and Hub classes.
The Loader class is a super class of the Controller class and is used simply for examining data and then loading data into interfaces. This is useful for dealing with interfaces that only consume data already within the system, such as for plotting.
4.2.4. Plugins and Storage¶
The Aneris framework is designed to allow certain components to be “plugged” meaning that particular classes can be added to a module and their functionality becomes immediately available to the rest of the system without modifying any additional code. The Socket and DataValidation classes are subclasses of the Plugin class so that they can discover new Interface classes or DataDefinition classes depending on how the user of the framework wishes to structure their project.
The provision for local storage has also been considered within the Aneris framework. For robustness, this would require serialising the data pool, using the most appropriate technology for the data structures defined (this could be Pickle, HDF5, PyTables, etc). It could also be that only partial serialisation of the DataPool is needed in order to conserve RAM space on the host machine. The logic for this partial serialisation might be that when a modification of a data member occurs and two copies of this member are within the pool, then the older member is serialised. Obviously, it must be easy to do the reverse action, should the data state with the updated member be discarded.
The SerialBox class will be used as a wrapper for all serialised data, carrying information about the data´s storage location and how it should be reconstructed back into RAM memory. Potentially this class could be sub-classed to handle differing serialisation technologies.
For save and load functionality, further structures must be serialised including the Simulation and the DataStates, Hubs or Pipelines it contained. The design of these entity classes ensure that they can be serialised in a light weight text based format, such as JSON or directly using the Python “Pickle” module.
4.2.5. 3rd Party Libraries¶
The following 3rd party Python libraries are leveraged to facilitate the development of the Aneris framework:
- attrdict
- numpy
- openpyxl
- pandas
- pyyaml
- pywin32
- sqlalchemy
- xlrd
- xlwt
Additionally, the “polite” module developed alongside Aneris, and discussed within the next section, is required.
4.3. Polite¶
Polite is an additional library that has been developed alongside Aneris in order reduce replication of code used across the DTOcean project. This library offers the following functionality:
- Easy file path discovery for installed modules
- Easy setup of Python logging
- Easy creation, reading and locating of configuration files (for logging and otherwise)
It utilises the following 3rd party Python libraries:
- configobj
- pyyaml