6. Database Design¶
6.1. Database¶
The DTOcean tool is coupled to Database capable to store data that will be consumed by the tool.
The database is a relational Structured Query Language (SQL) database, using PostgreSQL version 9.4.
A relational database is a collection of data structured as a set of tables from which data can be retrived without having to reorganize the database tables. The data is broken down into normalized form, this avoids data dupliation and thus aids improved database performance.
As part of the normalization process of data, parent and child tables are created, these are normally 1-to-1 or 1-to-many relationships, for example one shop(parent table) will have many customers(child table), while one shop(parent table) may have only one supplier(child table). Each customer/supplier would be given a unique ID which would become their primary/foreign key and allow their details to be stored without them becoming lost or corrupted. The parent table would hold data attributes that would be common throughout all records, while the child tables would hold the less common attributes and attributes only specific.
Tables are linked by the use of primary and foreign key constraints, the primary key is the identifier in the parent table, while the foreign key is the identifier to the rest of the data in the child table. A primary key and corresponding foreign key will always have the same value. In the case of a primary key this is a unique value usually an ID number that is used to search the table, no table will have two primary keys of the same value. A foreign key is used to search for the data in the child table.
The purpose of the database is to store input data that will be used during simulations and to reduce the data entry burden on the software user, by providing a baseline data set prior to beginning the operation of the Core. Correctly formatted data must be entered into the database in order to make it available to the Core, but this is a onetime operation versus re-entering the data into the Core upon each usage.
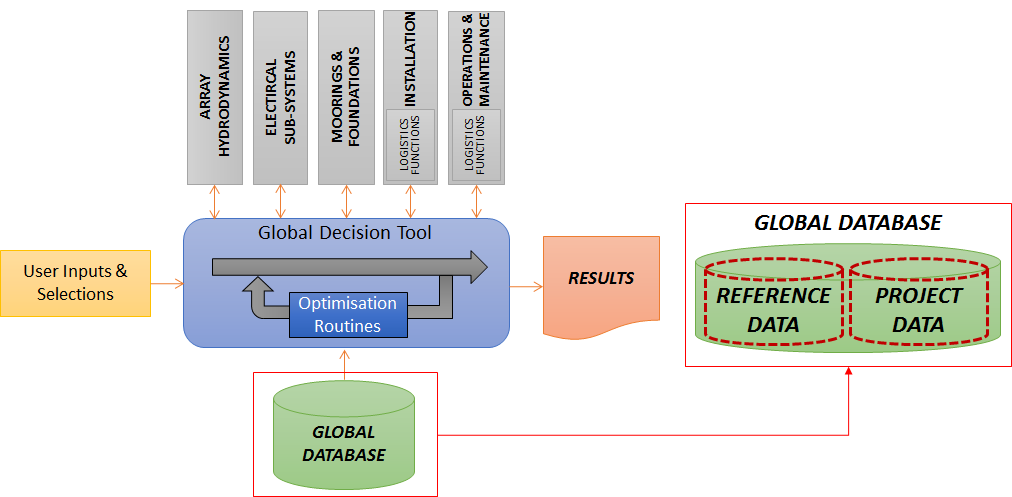
Fig. 6.28 Virtual partitioning of the Global Database
A standardised data access method is employed: all data requests are channelled through the DTOcean Core module, using SQLAlchemy to convert relational data to Pythonic data structures, hence all information is loaded into the global decision tool and not to the computational modules directly.
This allows the user to override the data collected from the global database, reduces inefficiencies and ambiguities that may occur when several modules require the same data.
A PostGIS library has been implemented to the database server to provide support for GIS datatypes.
The database is designed to support the operation of the individual modules which carry out the processing required by the DTOcean software.
It will not to store intermediate solutions generated while calculating the final results or the final results themselves.
A set of parameters has been provided by each computational package, which listed the data items which are required to support the processes in each of the modules. Each parameter is specified by a name, an associated data type and brief description. From this list a set of tables has been designed accordingly.
The database will reside on the same machine as the DTOcean software; however a future extension could allow some data to be retrieved from other DTOcean databases that are not controlled by the system user by changing the database address.
From a structural point of view he overall database is split in two: reference data tables are stored in a REFERENCE database, while tables which are to be used for specific projects are contained in a PROJECT database.
Broadly speaking the database will:
- Accept and store project-specific data during the preparation of a specific project or projects, which can be accessed by multiple processes during the project lifecycle.
- Store long-standing reference data that can be utilised by the users of the DTOcean software when creating projects.
The results of external packages will not be stored in the database; these are stored in memory and, as an extension, could be stored in a local file for inspection by the user.
6.1.1. Design Approach¶
The database is designed to support the operation of the individual modules which carry out the processing required by the DTOcean software.
A set of parameters was provided by each computational package, which listed the data items which are required to support the processes in each of the modules. Each parameter is specified by a name, an associated data type and brief description. From this list a set of tables has been designed.
6.1.2. Data Storage¶
The database will:
- Store long-standing reference data that can be utilised by the users of the DTOcean software when creating projects
- Accept and store some project-specific data during the preparation of a specific project or projects, which can be accessed by multiple processes during the project lifecycle
6.1.3. Reference Data¶
As a user progresses through the stages of creating a project in DTOcean, they will require access to reference data to support decision-making. This will include data on vessels, ports and components.
The data will be made available through the Core element of the DTOcean software, via direct connection to individual tables.
Management of this data during the design stage is undertaken using a set of SQL scripts. To facilitate future modification of the reference data, these scripts could be documented and made directly available to the user or the graphical user interface could be enhanced to provide this functionality.
6.1.4. Project Data¶
Before using the software to execute a project, the user will upload a set of data for the proposed site, for example bathymetry and related geotechnical data. This will be stored in the database so that it can be accessed by later processes (mooring design, logistics planning etc.). The code to manage this data upload will be developed as a part of the overall software.
The results of external packages will not be stored in the database; these are stored in memory and, as an extension, could be stored in a local file for inspection by the user.
6.1.5. Database Structure¶
At present the overall database is split in two: reference data tables are stored in a REFERENCE database, while tables which are to be used for specific projects are contained in a PROJECT database. These can be merged if it will improve performance or make deployment of the software less complex.
6.1.6. Database versions¶
The database will be made available in a number of different versions, as follows:
- Master: This is the design master of the database. This will not contain data and will not be used in the overall system. It is provided as a standard reference version for other instances of the database
- Test: This version will contain test data. It will be a clone of the Master database and will be manually populated by WP1 to contain sample values for every table. This version can be used to test connectivity from the core
- Scenario: This clone of the Master database will contain data from the Validation Scenarios. This will be used to validate the operation of the overall system
- Release: This version of the Master database will be released as part of the final version of the DTOcean software
6.1.7. Database Architecture¶
The database is a relational database, using PostgreSQL version 9.4. The database will be deployed alongside the Python based software on a single host machine meeting the target. The PostGIS extension will be used to provide support for GIS types.
There is a standardised data access method: all data requests are channelled through the DTOcean Core module, using SQLAlchemy to convert relational data to pythonic data structures.
6.1.8. Normalisation¶
To minimise data redundancy, the initial design is fully normalised. However, given the large data volumes and complexity of some relationships have been de-normalised to improve response times.
6.1.9. Referential integrity¶
Where appropriate, a number of relationships between tables have been enforced to ensure data integrity. For example, it will not be possible to record geotechnical data without a related bathymetry point record.
6.1.10. Data validation¶
In accordance with standard database design, the database has facilities to enforce rules on new and updated data records. This is done on a number of levels:
Data Types
Data types provide the first layer of validation. The datatype chosen for most fields is based on the type specified by the external package for the associated parameter. In some cases this is not suitable or may not be appropriate to all possible data values. For example, an integer is specified but the value may, in certain circumstances, contain a decimal point. In these cases the values can be formatted to appear as integers in the user interface. If a value is submitted to the database and is not of the correct type then an error will be raised, to be handled by the Core. However, in some cases the error may be hidden; for example a double precision value can be stored in an integer field without raising an error, but the value will be floored and the mantissa lost.
Field Size
Field sizes provide another layer of validation. The field size property applies only to text and “varchar” types. In choosing a size for a field, the longest practical value to be stored has been estimated, and the field sized accordingly. As with data types, careful error handling is required here to avoid default truncation of data values.
Nullability
Tables are assigned a primary or foreign key for structural, validation and searching purposes. These key constraints are as standard set to NOT NULL, meaning a valid data value must be entered in the given cell. If a value is not provided when an attribute is NOT NULL then the given record will fail to be inserted. The provision of data in a NOT NULL scenario is dependent on that given table.
Checks and Rules
PostGRES provides a facility to apply a CHECK or a RULE to new or updated values in a table. This is a useful method for enforcing business rules, but as with other validation methods it can be difficult to bulk load data and to carry out initial design test of the database where checks are in place. So far no check or rule has been created on tables in the database, but the options are available if the need arises.
Uniqueness
In addition to specifying a Primary Key to uniquely identify each record in a table, it is possible to specify that data in a non-primary key column must be unique or null throughout the table.
In all tables the Primary Key has been created as a sequential number, named “id”. No naturally occurring unique values (e.g. vessel name) have been designated as Primary Key.
6.1.11. Data access¶
the core is accessing the data via the use of views, these are instances of tables or tables joined that are requested at that moment in time by the core, views do not hold data permanently in memory unlike a table. The views are used as a safety barrier; they protect the database tables form being corrupted by code that potentially may have a bug in it.
6.1.12. Data filtering¶
To optimise performance of the software, it is important to minimise data retrieval times. In addition to adhering to correct design patters when building the tables, performance are improved by applying initial filters to the database so that it will return only data which is relevant to the current scenario (i.e. choice of site and technology).
When a user wished to create a Scenario using the software, they will select a specific Site from the list of sites stored in the database. A database function will accept the ID of the Site as an input parameter, and then create a new scenario-specific set of tables contain data relevant to that site.
Similarly, the user will select a technology form the list of devices in the database, and the relevant function will create a set of tables to store the relevant data.
When a Scenario is initiated, the Core will load the set of reference data necessary to the operation of the choses external packages into memory, for ease of retrieval.
6.1.13. Table grouping¶
The tables in the database can be broadly divided into logical groups. Tables within each group are related via Foreign Keys. This section contains a description of the tables in the Component data group.
The relationship among tables for Project data consumed by WP2,WP3 and WP4 (i.e. the three modules the Core can connect to) are shown in Fig. 6.29 to Fig. 6.31.
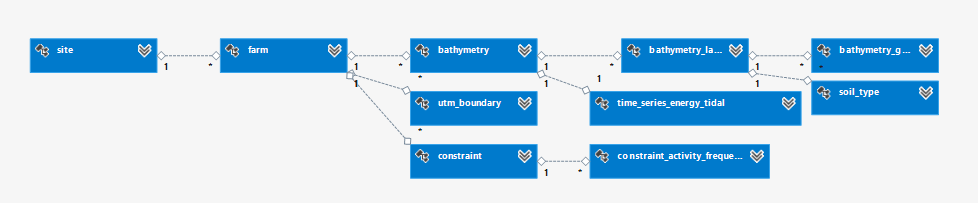
Fig. 6.29 Site and Farm tables relationship

Fig. 6.30 Cable Corridor tables relationship
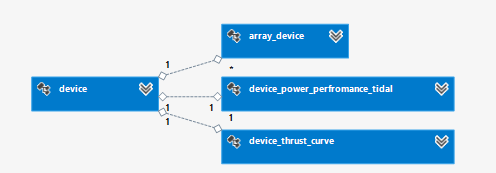
Fig. 6.31 Device tables relationship
The Component tables are used by a number of modules, as components are relevant throughout the DTOcean process. In the context of the database, a component is any physical object used in building a farm. The concept includes devices, mooring and foundation.
The database uses inheritance in this data area: the parent table, Component, records the common properties of all component types in the system. Child tables contain the properties relevant to that sub-type, for example electrical connectors. Fig. 6.32 displays the relationships between Component and the tables used to record them.
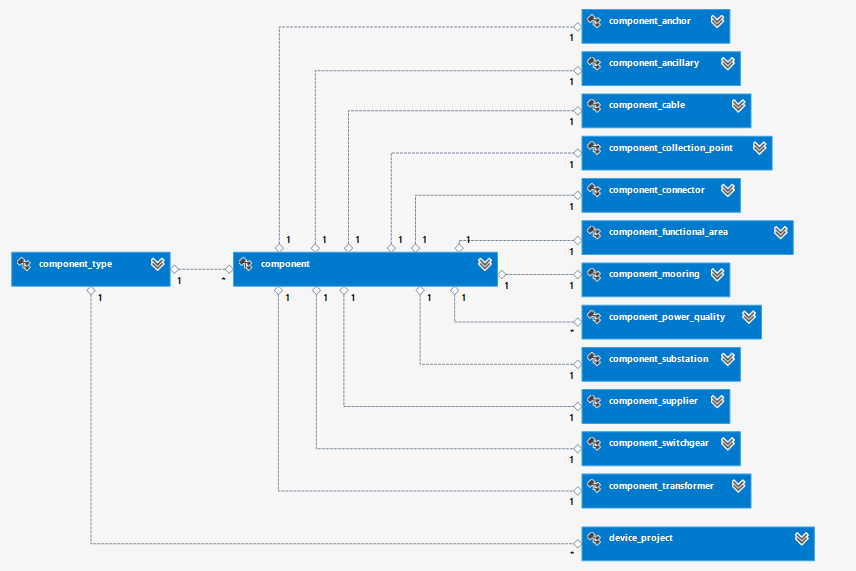
Fig. 6.32 Table structure for storing Components
The remaining tables in the Database are “stand-alone” tables and for which structural relationship do not exist. These are shown in Fig. 6.33.

Fig. 6.33 List of “stand-alone” tables